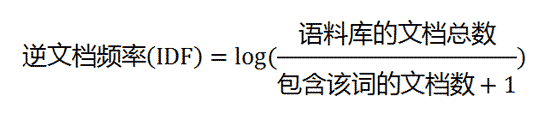明天是许多课程交论文的截止日期,但是还有许多论文的摘要没写好,rxms 已经来不及自己写了,她想写个程序自动摘要,提取 20 个关键词作为文章的摘要。
什么是关键词呢?如果某个词比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,这正是我们所需要的关键词,这可以通过 TF-IDF 来衡量,TF-IDF 的计算步骤如下:
第一步,计算词频 TF。
第二步,计算逆文档频率 IDF(log 取以 e 为底)。
第三步,计算 TF-IDF。
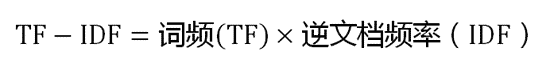
最后将词按 TF-IDF 降序排列,TF-IDF 值一样的时候按字典序升序排列,排在最前面的 20 个词就是要找的关键词。
输入格式
第一行为测试数据组数 T。
给出三个整数 N (1≤N≤1000)、B (1≤B≤1000)、D(1≤D≤1000),分别表示候选词的个数 N、文章的总词数 B、语料库的文档总数 D,。
接下去 N 行,每一行是一个候选词(字符串长度小于 100)、在文章中出现次数 b (b≤B)、语料库中包含该词的文档数 d (d≤D)。
输出格式
对于每组数据,先输出一行 “Case #X:”,其中 X 表示第几组数据,
再在一行中输出关键词,中间以空格隔开,关键词个数不足 20 个的输出它原来的个数。
样例
Output
Case #1:
Love ECNU I You